Transaction processing DBMSs are complex, sophisticated software systems, often involving millions of lines of code. They need to reliably implement "ACID" semantics, while achieving high transactional throughput and providing high availability. Unfortunately, despite much effort in testing and quality assurance on the part of vendors and developers, bugs cause deployed production systems to fail, reducing reliability and availability.
Database replication is an effective technique to provide high availability in the face of faults. Unfortunately, using replication to mask software faults is not as straightforward as with hardware. There are two reasons for this. First, if all replicas run the same software, they are quite likely to all "share fate" upon encountering a bug, violating the "independent failures" requirement. Second, unlike the majority of hardware faults that either cause a crash or report an error code (such as a "disk error"), a large number of software faults are silent, with the system continuing on as if nothing untoward happened (e.g., MySQL is known to have numerous real bugs that produce incorrect answers; we don't think other systems are likely to be different). Such Byzantine faults are especially likely if an attacker compromises a system by taking advantage of a security vulnerability.
We have designed HRDB (Heterogeneous Replicated DB), a fault-tolerant DBMS that implements a practical replication scheme capable of masking a wide range of database faults. As in previous work, HRDB uses replication, but it incorporates two key ideas that address the two issues raised above. First, to achieve failure-independence, HRDB uses heterogeneous replication. A set of diverse and independently implemented replicas, each implementing a common subset of the SQL standard, can reduce the impact of software bugs and security vulnerabilities, because it is unlikely (or perhaps less likely) that the same bugs show up in independently implemented replicas. C-JDBC [3] is another replication system that uses heterogeneous databases, but it focuses on failstop faults and lacks an efficient method of dealing with update transactions.
Second, to handle Byzantine failures, HRDB uses voting---any response obtained by a client to a SQL statement in a committed transaction is guaranteed to have received a majority vote from among 2f + 1 replicas. Here, f is a configurable parameter that determines the maximum number of replicas that can incorrectly execute a statement. This builds on previous work [1] [2] [4] on Byzantine fault tolerance, but applies it to databases.
A key design goal for HRDB is that it should require no modifications to any database replica software; in fact, we seek a design that does not require any HRDB-specific software to run on any machine hosting a replica database. Treating each replica as a "shrink-wrapped" subsystem will ease the deployment and operation of HRDB. Fortunately, because many DBMSs offer a (mostly) standard SQL interface and provide connectivity protocols such as ODBC and JDBC, we are able to meet this goal.
Achieving fault-tolerance without modifying the internals of the database replicas is non-trivial because the replicas could execute a set of concurrent transactions in many different orders, each of which constitutes a correct serial execution, but yet the responses to the queries and the end state of each replica could be different. Thus, for voting to work well, it is important that each replica DBMS execute conflicting transactions in a way that is equivalent to some single serial order. Achieving this goal while ensuring high throughput is especially hard given our (pragmatic) constraint of using only a SQL interface, because it is very hard to tell for certain whether any two SQL statements conflict or not. A further problem is that some SQL statements that write data into tables do not return a response that indicates exactly what data got written, making it hard to determine if they worked correctly on the replica databases.
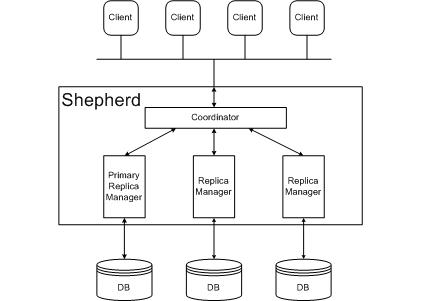
In HRDB, clients do not interact directly with the database replicas. Instead they communicate with a shepherd, which acts as a front-end to the replicas and coordinates them. The shepherd runs a replica manager for each back-end replica. It has a coordinator module, which clients interact with, sending it SQL statements and receiving responses over a connectivity protocol like JDBC or ODBC. The coordinator forwards SQL statements from the client to each replica manager. Each replica manager also uses JDBC or ODBC to interact with its corresponding replica. We limit the scope of the problem by considering only DBMSs which use strict two-phase locking to implement serializable execution.
Our scheme for serializing transactions is as follows. One replica is designated to be the primary and it runs statements of transactions before the other secondary replicas. Thus, the primary's concurrency manager chooses the serialization order. The coordinator and the replica managers then ensure that transaction statements and commits are issued at the secondary replicas in a way that guarantees they will agree with the order selected by the primary. HRDB uses a mechanism called commit barrier scheduling to delay sending statements to the secondary as needed to ensure that the secondary processes them in an order the produces an equivalent transaction ordering as the primary, while preserving as much concurrency as possible.
HRDB provides both fail-stop and Byzantine fault tolerance. Fail-stop faults are easy to detect and the replica manager replays transactions to bring the replica up to date. Byzantine faults can result in a replica returning an answer that doesn't match the answer agreed upon by f+1 other replicas. This easy case results in the replica being scheduled to have its state repaired. Byzantine faults that result in scheduling errors, particularly on the primary, can be very hard to detect. Due to the in-order-processing rule, replica state will not diverge, but forward progress may be impeded. A replica with a scheduling fault can make forward progress by aborting and restarting transactions. Replacing a faulty primary involves briefly quiescing the system.
We implemented a prototype of HRDB that incurs only a 30% performance loss to provide Byzantine fault tolerant database access. Furthermore, most (24%) of this performance penalty is due to the mechanics of the middleware implementation. For comparison, the strawman system that executes transactions sequentially incurs a 63% performance loss.
We are pursuing a number of optimizations and extensions. Optimizing the Shepherd implementation would recoup some of the performance gap. The current method of repairing the state of a known-faulty replica is very inefficient; an efficient method would involve incremental table repair via exchanging hashes. Possible extensions include extending commit barrier scheduling to work with optimistic concurrency schemes (like Snapshot Isolation) implementing a tagging scheme to verify the effect of writes, and replicating the shepherd to provide increased failstop or Byzantine fault tolerance.
This work is supported in part by Quanta Corporation and by the National Science Foundation under award number CNS-0225660.